Prisma ORM 是 ORM 吗?
简单回答一下这个问题:是的,Prisma ORM 是一种新型 ORM,它与传统 ORM 根本不同,并且不会遇到与传统 ORM 相关的许多常见问题。
¥To answer the question briefly: Yes, Prisma ORM is a new kind of ORM that fundamentally differs from traditional ORMs and doesn't suffer from many of the problems commonly associated with these.
传统的 ORM 通过将表映射到编程语言中的模型类,提供了一种面向对象的方式来处理关系数据库。这种方法会导致许多由 对象关系阻抗不匹配 引起的问题。
¥Traditional ORMs provide an object-oriented way for working with relational databases by mapping tables to model classes in your programming language. This approach leads to many problems that are caused by the object-relational impedance mismatch.
与此相比,Prisma ORM 的工作原理根本不同。使用 Prisma ORM,你可以在声明性 Prisma 架构 中定义模型,该 Prisma 架构 是你的数据库架构和编程语言中的模型的单一事实来源。在你的应用代码中,你可以使用 Prisma Client 以类型安全的方式在数据库中读取和写入数据,而无需管理复杂模型实例的开销。这使得查询数据的过程更加自然,也更加可预测,因为 Prisma 客户端始终返回纯 JavaScript 对象。
¥Prisma ORM works fundamentally different compared to that. With Prisma ORM, you define your models in the declarative Prisma schema which serves as the single source of truth for your database schema and the models in your programming language. In your application code, you can then use Prisma Client to read and write data in your database in a type-safe manner without the overhead of managing complex model instances. This makes the process of querying data a lot more natural as well as more predictable since Prisma Client always returns plain JavaScript objects.
在本文中,你将更详细地了解 ORM 模式和工作流程、Prisma ORM 如何实现数据映射器模式以及 Prisma ORM 方法的优势。
¥In this article, you will learn in more detail about ORM patterns and workflows, how Prisma ORM implements the Data Mapper pattern, and the benefits of Prisma ORM's approach.
什么是 ORM?
¥What are ORMs?
如果你已经熟悉 ORM,请随时跳转到 Prisma ORM 上的 下一节。
¥If you're already familiar with ORMs, feel free to jump to the next section on Prisma ORM.
ORM 模式 - Active Record 和数据映射器
¥ORM Patterns - Active Record and Data Mapper
ORM 提供高级数据库抽象。它们通过对象公开编程接口来创建、读取、删除和操作数据,同时隐藏数据库的一些复杂性。
¥ORMs provide a high-level database abstraction. They expose a programmatic interface through objects to create, read, delete, and manipulate data while hiding some of the complexity of the database.
ORM 的想法是将模型定义为映射到数据库中的表的类。这些类及其实例为你提供了一个编程 API,用于在数据库中读取和写入数据。
¥The idea with ORMs is that you define your models as classes that map to tables in a database. The classes and their instances provide you with a programmatic API to read and write data in the database.
有两种常见的 ORM 模式:活动记录 和 数据映射器 的不同之处在于它们在对象和数据库之间传输数据的方式。虽然这两种模式都要求你将类定义为主要构建块,但两者之间最显着的区别是数据映射器模式将应用代码中的内存中对象与数据库解耦,并使用数据映射器层在两者之间传输数据。实际上,这意味着使用数据映射器,内存中的对象(表示数据库中的数据)甚至不知道存在数据库。
¥There are two common ORM patterns: Active Record and Data Mapper which differ in how they transfer data between objects and the database. While both patterns require you to define classes as the main building block, the most notable difference between the two is that the Data Mapper pattern decouples in-memory objects in the application code from the database and uses the data mapper layer to transfer data between the two. In practice, this means that with Data Mapper the in-memory objects (representing data in the database) don't even know that there’s a database present.
活动记录
¥Active Record
Active Record ORM 将模型类映射到数据库表,其中两种表示的结构密切相关,例如 模型类中的每个字段在数据库表中都有一个匹配的列。模型类的实例封装数据库行并携带数据和访问逻辑以处理数据库中的持久更改。此外,模型类可以承载特定于模型中数据的业务逻辑。
¥Active Record ORMs map model classes to database tables where the structure of the two representations is closely related, e.g. each field in the model class will have a matching column in the database table. Instances of the model classes wrap database rows and carry both the data and the access logic to handle persisting changes in the database. Additionally, model classes can carry business logic specific to the data in the model.
模型类通常具有执行以下操作的方法:
¥The model class typically has methods that do the following:
-
从 SQL 查询构造模型的实例。
¥Construct an instance of the model from an SQL query.
-
构造一个新实例以便稍后插入表中。
¥Construct a new instance for later insertion into the table.
-
封装常用的 SQL 查询并返回 Active Record 对象。
¥Wrap commonly used SQL queries and return Active Record objects.
-
更新数据库并将 Active Record 中的数据插入其中。
¥Update the database and insert into it the data in the Active Record.
-
获取和设置字段。
¥Get and set the fields.
-
实现业务逻辑。
¥Implement business logic.
数据映射器
¥Data Mapper
与 Active Record 相比,数据映射器 ORM 将应用的内存中数据表示与数据库表示解耦。解耦是通过要求你将映射职责分成两种类型的类来实现的:
¥Data Mapper ORMs, in contrast to Active Record, decouple the application's in-memory representation of data from the database's representation. The decoupling is achieved by requiring you to separate the mapping responsibility into two types of classes:
-
实体类:应用在内存中表示不了解数据库的实体
¥Entity classes: The application's in-memory representation of entities which have no knowledge of the database
-
映射器类:它们有两个职责:
¥Mapper classes: These have two responsibilities:
-
在两种表示形式之间转换数据。
¥Transforming the data between the two representations.
-
生成从数据库获取数据并将更改保留在数据库中所需的 SQL。
¥Generating the SQL necessary to fetch data from the database and persist changes in the database.
-
数据映射器 ORM 允许在代码和数据库中实现的问题域之间提供更大的灵活性。这是因为数据映射器模式允许你隐藏数据库的实现方式,这不是考虑整个数据映射层背后的域的理想方式。
¥Data Mapper ORMs allow for greater flexibility between the problem domain as implemented in code and the database. This is because the data mapper pattern allows you to hide the ways in which your database is implemented which isn’t an ideal way to think about your domain behind the whole data-mapping layer.
传统数据映射器 ORM 这样做的原因之一是由于组织的结构,其中两个职责将由单独的团队(例如 数据库管理员 和后端开发者)处理。
¥One of the reasons that traditional data mapper ORMs do this is due to the structure of organizations where the two responsibilities would be handled by separate teams, e.g., DBAs and backend developers.
实际上,并非所有 Data Mapper ORM 都严格遵守此模式。例如,TypeScript 生态系统中流行的 ORM TypeORM 同时支持 Active Record 和 Data Mapper,它对 Data Mapper 采用以下方法:
¥In reality, not all Data Mapper ORMs adhere to this pattern strictly. For example, TypeORM, a popular ORM in the TypeScript ecosystem which supports both Active Record and Data Mapper, takes the following approach to Data Mapper:
-
实体类使用装饰器 (
@Column) 将类属性映射到表列并了解数据库。¥Entity classes use decorators (
@Column) to map class properties to table columns and are aware of the database. -
存储库类代替映射器类用于查询数据库,并且可能包含自定义查询。存储库使用装饰器来确定实体属性和数据库列之间的映射。
¥Instead of mapper classes, repository classes are used for querying the database and may contain custom queries. Repositories use the decorators to determine the mapping between entity properties and database columns.
给定数据库中的以下 User 表:
¥Given the following User table in the database:

相应的实体类如下所示:
¥This is what the corresponding entity class would look like:
import { Entity, PrimaryGeneratedColumn, Column } from 'typeorm'
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number
@Column({ name: 'first_name' })
firstName: string
@Column({ name: 'last_name' })
lastName: string
@Column({ unique: true })
email: string
}
架构迁移工作流程
¥Schema migration workflows
开发使用数据库的应用的核心部分是更改数据库架构以适应新功能并更好地适应你正在解决的问题。在本节中,我们将讨论 模式迁移 是什么以及它们如何影响工作流程。
¥A central part of developing applications that make use of a database is changing the database schema to accommodate new features and to better fit the problem you're solving. In this section, we'll discuss what schema migrations are and how they affect the workflow.
由于 ORM 位于开发者和数据库之间,因此大多数 ORM 都提供迁移工具来协助创建和修改数据库模式。
¥Because the ORM sits between the developer and the database, most ORMs provide a migration tool to assist with the creation and modification of the database schema.
迁移是将数据库架构从一种状态转变为另一种状态的一组步骤。第一次迁移通常会创建表和索引。后续迁移可能会添加或删除列、引入新索引或创建新表。根据迁移工具的不同,迁移可能采用 SQL 语句或编程代码的形式,这些代码将转换为 SQL 语句(如 ActiveRecord 和 SQL 炼金术)。
¥A migration is a set of steps to take the database schema from one state to another. The first migration usually creates tables and indices. Subsequent migrations may add or remove columns, introduce new indices, or create new tables. Depending on the migration tool, the migration may be in the form of SQL statements or programmatic code which will get converted to SQL statements (as with ActiveRecord and SQLAlchemy).
由于数据库通常包含数据,因此迁移可帮助你将架构更改分解为更小的单元,从而有助于避免意外的数据丢失。
¥Because databases usually contain data, migrations assist you with breaking down schema changes into smaller units which helps avoid inadvertent data loss.
假设你从头开始一个项目,完整的工作流程如下所示:你创建的迁移将在数据库架构中创建 User 表并定义 User 实体类,如上例所示。
¥Assuming you were starting a project from scratch, this is what a full workflow would look like: you create a migration that will create the User table in the database schema and define the User entity class as in the example above.
然后,随着项目的进展并且你决定要向 User 表添加新的 salutation 列,你将创建另一个迁移,该迁移将更改该表并添加 salutation 列。
¥Then, as the project progresses and you decide you want to add a new salutation column to the User table, you would create another migration which would alter the table and add the salutation column.
让我们看看 TypeORM 迁移会是什么样子:
¥Let's take a look at how that would look like with a TypeORM migration:
import { MigrationInterface, QueryRunner } from 'typeorm'
export class UserRefactoring1604448000 implements MigrationInterface {
async up(queryRunner: QueryRunner): Promise<void> {
await queryRunner.query(`ALTER TABLE "User" ADD COLUMN "salutation" TEXT`)
}
async down(queryRunner: QueryRunner): Promise<void> {
await queryRunner.query(`ALTER TABLE "User" DROP COLUMN "salutation"`)
}
}
执行迁移并更改数据库架构后,还必须更新实体和映射器类以适应新的 salutation 列。
¥Once a migration is carried out and the database schema has been altered, the entity and mapper classes must also be updated to account for the new salutation column.
对于 TypeORM,这意味着将 salutation 属性添加到 User 实体类:
¥With TypeORM that means adding a salutation property to the User entity class:
import { Entity, PrimaryGeneratedColumn, Column } from 'typeorm'
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number
@Column({ name: 'first_name' })
firstName: string
@Column({ name: 'last_name' })
lastName: string
@Column({ unique: true })
email: string
@Column()
salutation: string
}
使用 ORM 同步此类更改可能是一个挑战,因为这些更改是手动应用的,并且不容易通过编程进行验证。重命名现有列可能更加麻烦,并且涉及搜索和替换对该列的引用。
¥Synchronizing such changes can be a challenge with ORMs because the changes are applied manually and are not easily verifiable programmatically. Renaming an existing column can be even more cumbersome and involve searching and replacing references to the column.
注意:Django 的 makemigrations CLI 通过检查模型中的更改来生成迁移,这与 Prisma ORM 类似,消除了同步问题。
¥Note: Django's makemigrations CLI generates migrations by inspecting changes in models which, similar to Prisma ORM, does away with the synchronization problem.
总之,发展模式是构建应用的关键部分。使用 ORM,更新架构的工作流程涉及使用迁移工具创建迁移,然后更新相应的实体和映射器类(取决于实现)。正如你将看到的,Prisma ORM 对此采取了不同的方法。
¥In summary, evolving the schema is a key part of building applications. With ORMs, the workflow for updating the schema involves using a migration tool to create a migration followed by updating the corresponding entity and mapper classes (depending on the implementation). As you'll see, Prisma ORM takes a different approach to this.
现在你已经了解了什么是迁移以及它们如何融入开发工作流程,你将更多地了解 ORM 的优点和缺点。
¥Now that you've seen what migrations are and how they fit into the development workflows, you will learn more about the benefits and drawbacks of ORMs.
ORM 的好处
¥Benefits of ORMs
开发者选择使用 ORM 的原因有多种:
¥There are different reasons why developers choose to use ORMs:
-
ORM 有助于实现域模型。域模型是一个对象模型,其中包含业务逻辑的行为和数据。换句话说,它允许你专注于真正的业务概念,而不是数据库结构或 SQL 语义。
¥ORMs facilitate implementing the domain model. The domain model is an object model that incorporates the behavior and data of your business logic. In other words, it allows you to focus on real business concepts rather than the database structure or SQL semantics.
-
ORM 有助于减少代码量。它们使你无需为常见的 CRUD(创建、读取、更新、删除)操作编写重复的 SQL 语句,也无需转义用户输入以防止 SQL 注入等漏洞。
¥ORMs help reduce the amount of code. They save you from writing repetitive SQL statements for common CRUD (Create Read Update Delete) operations and escaping user input to prevent vulnerabilities such as SQL injections.
-
ORM 要求你编写很少的 SQL 甚至不需要编写 SQL(根据你的复杂性,你可能仍然需要编写奇怪的原始查询)。这对于不熟悉 SQL 但仍想使用数据库的开发者来说是有益的。
¥ORMs require you to write little to no SQL (depending on your complexity you may still need to write the odd raw query). This is beneficial for developers who are not familiar with SQL but still want to work with a database.
-
许多 ORM 抽象了数据库特定的细节。从理论上讲,这意味着 ORM 可以使从一个数据库到另一个数据库的更改变得更加容易。应该注意的是,在实践中应用很少更改它们使用的数据库。
¥Many ORMs abstract database-specific details. In theory, this means that an ORM can make changing from one database to another easier. It should be noted that in practice applications rarely change the database they use.
与所有旨在提高生产力的抽象一样,使用 ORM 也有缺点。
¥As with all abstractions that aim to improve productivity, there are also drawbacks to using ORMs.
ORM 的缺点
¥Drawbacks of ORMs
当你开始使用 ORM 时,其缺点并不总是显而易见。本节涵盖了一些普遍接受的内容:
¥The drawbacks of ORMs are not always apparent when you start using them. This section covers some of the commonly accepted ones:
-
使用 ORM,你可以形成数据库表的对象图表示,这可能导致 对象关系阻抗不匹配。当你要解决的问题形成一个复杂的对象图,而该对象图不能简单地映射到关系数据库时,就会发生这种情况。在两种不同的数据表示(一种在关系数据库中,另一种在内存中(带有对象)中)之间进行同步是相当困难的。这是因为与关系数据库记录相比,对象之间的关联方式更加灵活且多样。
¥With ORMs, you form an object graph representation of database tables which may lead to the object-relational impedance mismatch. This happens when the problem you are solving forms a complex object graph which doesn't trivially map to a relational database. Synchronizing between two different representations of data, one in the relational database, and the other in-memory (with objects) is quite difficult. This is because objects are more flexible and varied in the way they can relate to each other compared to relational database records.
-
虽然 ORM 处理了与问题相关的复杂性,但同步问题并没有消失。对数据库模式或数据模型的任何更改都需要将更改映射回另一端。这个负担通常由开发者承担。在处理项目的团队环境中,数据库架构更改需要协调。
¥While ORMs handle the complexity associated with the problem, the synchronization problem doesn't go away. Any changes to the database schema or the data model require the changes to be mapped back to the other side. This burden is often on the developer. In the context of a team working on a project, database schema changes require coordination.
-
由于 ORM 封装的复杂性,它们往往具有较大的 API 表面。不必编写 SQL 的另一面是你需要花费大量时间学习如何使用 ORM。这适用于大多数抽象,但是如果不了解数据库的工作原理,改进缓慢的查询可能会很困难。
¥ORMs tend to have a large API surface due to the complexity they encapsulate. The flip side of not having to write SQL is that you spend a lot of time learning how to use the ORM. This applies to most abstractions, however without understanding how the database works, improving slow queries can be difficult.
-
由于 SQL 提供的灵活性,ORM 不支持某些复杂查询。这个问题可以通过原始 SQL 查询功能得到缓解,在该功能中,你向 ORM 传递一个 SQL 语句字符串,然后查询就会为你运行。
¥Some complex queries aren't supported by ORMs due to the flexibility that SQL offers. This problem is alleviated by raw SQL querying functionality in which you pass the ORM a SQL statement string and the query is run for you.
现在已经涵盖了 ORM 的成本和收益,你可以更好地了解 Prisma ORM 是什么以及它如何发挥作用。
¥Now that the costs and benefits of ORMs have been covered, you can better understand what Prisma ORM is and how it fits in.
Prisma ORM
Prisma ORM 是下一代 ORM,它使应用开发者可以轻松地使用数据库,并具有以下工具:
¥Prisma ORM is a next-generation ORM that makes working with databases easy for application developers and features the following tools:
-
Prisma 客户端:自动生成且类型安全的数据库客户端,供你的应用使用。
¥Prisma Client: Auto-generated and type-safe database client for use in your application.
-
Prisma 迁移:声明性数据建模和迁移工具。
¥Prisma Migrate: A declarative data modeling and migration tool.
-
Prisma 工作室:用于浏览和管理数据库中数据的现代 GUI。
¥Prisma Studio: A modern GUI for browsing and managing data in your database.
注意:由于 Prisma 客户端是最重要的工具,因此我们通常将其简称为 Prisma。
¥Note: Since Prisma Client is the most prominent tool, we often refer to it as simply Prisma.
这三个工具使用 Prisma 架构 作为数据库模式、应用的对象模式以及两者之间映射的单一真实来源。它由你定义,是你配置 Prisma ORM 的主要方式。
¥These three tools use the Prisma schema as a single source of truth for the database schema, your application's object schema, and the mapping between the two. It's defined by you and is your main way of configuring Prisma ORM.
Prisma ORM 具有类型安全、丰富的自动补齐功能以及用于获取关系的自然 API 等功能,使你能够高效地对正在构建的软件充满信心。
¥Prisma ORM makes you productive and confident in the software you're building with features such as type safety, rich auto-completion, and a natural API for fetching relations.
在下一节中,你将了解 Prisma ORM 如何实现 Data Mapper ORM 模式。
¥In the next section, you will learn about how Prisma ORM implements the Data Mapper ORM pattern.
Prisma ORM 如何实现 Data Mapper 模式
¥How Prisma ORM implements the Data Mapper pattern
正如本文前面提到的,数据映射器模式非常适合数据库和应用由不同团队拥有的组织。
¥As mentioned earlier in the article, the Data Mapper pattern aligns well with organizations where the database and application are owned by different teams.
随着具有托管数据库服务和 DevOps 实践的现代云环境的兴起,越来越多的团队采用跨职能方法,即团队拥有完整的开发周期,包括数据库和运营问题。
¥With the rise of modern cloud environments with managed database services and DevOps practices, more teams embrace a cross-functional approach, whereby teams own both the full development cycle including the database and operational concerns.
Prisma ORM 支持数据库模式和对象模式的协同发展,从而从一开始就减少了偏差的需要,同时仍然允许你使用 @map 属性使应用和数据库保持一定程度的解耦。虽然这看起来像是一个限制,但它可以防止域模型的演变(通过对象模式)作为事后的想法强加于数据库。
¥Prisma ORM enables the evolution of the DB schema and object schema in tandem, thereby reducing the need for deviation in the first place, while still allowing you to keep your application and database somewhat decoupled using @map attributes. While this may seem like a limitation, it prevents the domain model's evolution (through the object schema) from getting imposed on the database as an afterthought.
要了解 Prisma ORM 的数据映射器模式实现在概念上与传统数据映射器 ORM 有何不同,以下是它们的概念和构建块的简要比较:
¥To understand how Prisma ORM's implementation of the Data Mapper pattern differs conceptually to traditional Data Mapper ORMs, here's a brief comparison of their concepts and building blocks:
| 概念 | 描述 | 传统 ORM 中的构建块 | Prisma ORM 中的构建块 | Prisma ORM 中的事实来源 |
|---|---|---|---|---|
| 对象模式 | 应用中的内存数据结构 | 模型类 | 生成的 TypeScript 类型 | Prisma 架构中的模型 |
| 数据映射器 | 对象模式和数据库之间转换的代码 | 映射器类 | Prisma 客户端中生成的函数 | @map attributes in the Prisma schema |
| 数据库架构 | 数据库中数据的结构,例如表和列 | 手动或使用编程 API 编写 SQL | Prisma Migrate 生成的 SQL | Prisma 架构 |
Prisma ORM 与数据映射器模式保持一致,具有以下附加优势:
¥Prisma ORM aligns with the Data Mapper pattern with the following added benefits:
-
通过基于 Prisma 模式生成 Prisma 客户端,减少定义类和映射逻辑的样板。
¥Reducing the boilerplate of defining classes and mapping logic by generating a Prisma Client based on the Prisma schema.
-
消除应用对象和数据库模式之间的同步挑战。
¥Eliminating the synchronization challenges between application objects and the database schema.
-
数据库迁移是一等公民,因为它们源自 Prisma 模式。
¥Database migrations are a first-class citizen as they're derived from the Prisma schema.
现在我们已经讨论了 Prisma ORM 数据映射器方法背后的概念,我们可以了解 Prisma 模式在实践中如何工作。
¥Now that we've talked about the concepts behind Prisma ORM's approach to Data Mapper, we can go through how the Prisma schema works in practice.
Prisma 架构
¥Prisma schema
Prisma 数据映射器模式实现的核心是 Prisma 模式 - 以下职责的单一事实来源:
¥At the heart of Prisma's implementation of the Data Mapper pattern is the Prisma schema – a single source of truth for the following responsibilities:
-
配置 Prisma 连接到数据库的方式。
¥Configuring how Prisma connects to your database.
-
生成 Prisma Client – 在应用代码中使用的类型安全 ORM。
¥Generating Prisma Client – the type-safe ORM for use in your application code.
-
使用 Prisma Migrate 创建和发展数据库架构。
¥Creating and evolving the database schema with Prisma Migrate.
-
定义应用对象和数据库列之间的映射。
¥Defining the mapping between application objects and database columns.
Prisma ORM 中的模型与 Active Record ORM 的含义略有不同。使用 Prisma ORM,模型在 Prisma 架构中定义为抽象实体,用于描述 Prisma Client 中的表、关系以及列与属性之间的映射。
¥Models in Prisma ORM mean something slightly different to Active Record ORMs. With Prisma ORM, models are defined in the Prisma schema as abstract entities which describe tables, relations, and the mappings between columns to properties in Prisma Client.
作为示例,以下是博客的 Prisma 架构:
¥As an example, here's a Prisma schema for a blog:
datasource db {
provider = "postgresql"
}
generator client {
provider = "prisma-client"
output = "./generated"
}
model Post {
id Int @id @default(autoincrement())
title String
content String? @map("post_content")
published Boolean @default(false)
author User? @relation(fields: [authorId], references: [id])
authorId Int?
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
}
这是上面示例的细分:
¥Here's a break down of the example above:
-
datasource块定义与数据库的连接。¥The
datasourceblock defines the connection to the database. -
generator块告诉 Prisma ORM 为 TypeScript 和 Node.js 生成 Prisma 客户端。¥The
generatorblock tells Prisma ORM to generate Prisma Client for TypeScript and Node.js. -
Post和User模型映射到数据库表。¥The
PostandUsermodels map to database tables. -
这两个模型具有 1-n 关系,其中每个
User可以有许多相关的Post。¥The two models have a 1-n relation where each
Usercan have many relatedPosts. -
模型中的每个字段都有一个类型,例如
id的类型为Int。¥Each field in the models has a type, e.g. the
idhas the typeInt. -
字段可以包含字段属性来定义:
¥Fields may contain field attributes to define:
-
具有
@id属性的主键。¥Primary keys with the
@idattribute. -
具有
@unique属性的唯一键。¥Unique keys with the
@uniqueattribute. -
@default属性的默认值。¥Default values with the
@defaultattribute. -
表列和具有
@map属性的 Prisma 客户端字段之间的映射,例如content字段(可在 Prisma 客户端中访问)映射到post_content数据库列。¥Mapping between table columns and Prisma Client fields with the
@mapattribute, e.g., thecontentfield (which will be accessible in Prisma Client) maps to thepost_contentdatabase column.
-
User / Post 关系可以通过下图可视化:
¥The User / Post relation can be visualized with the following diagram:
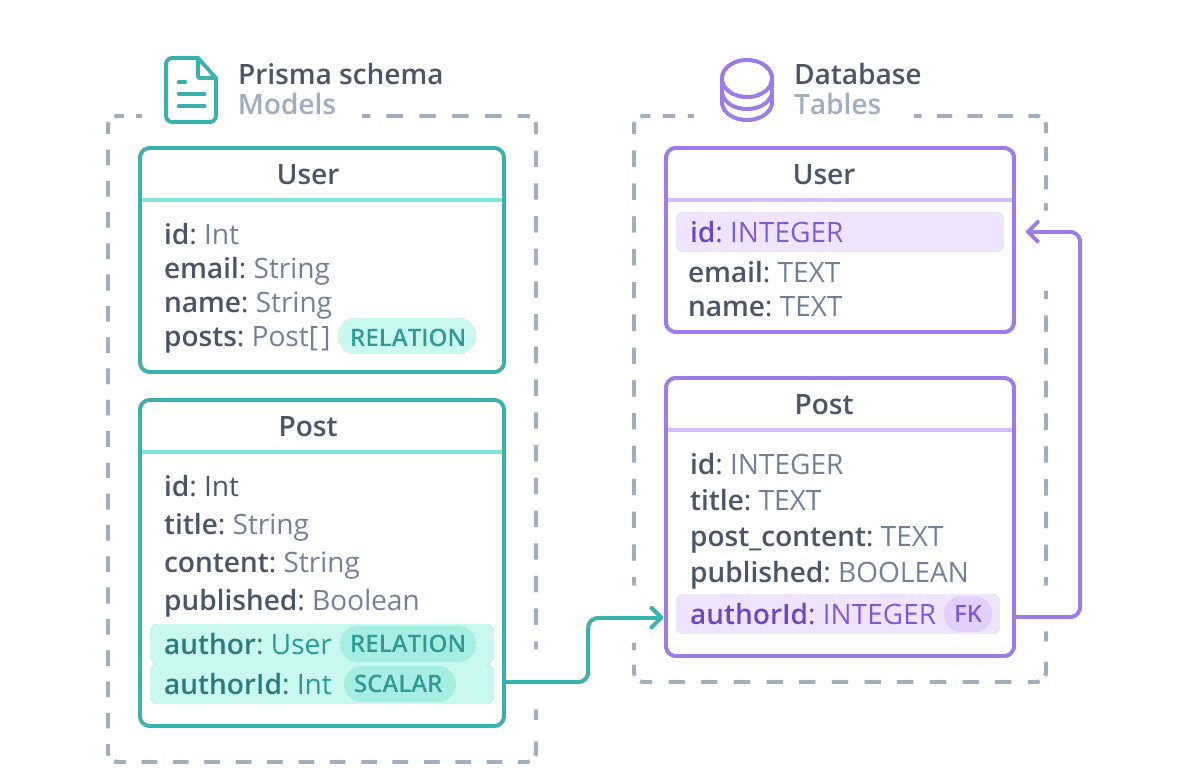
在 Prisma ORM 级别,User / Post 关系由以下部分组成:
¥At a Prisma ORM level, the User / Post relation is made up of:
-
标量
authorId字段,由@relation属性引用。该字段存在于数据库表中 - 它是连接 Post 和 User 的外键。¥The scalar
authorIdfield, which is referenced by the@relationattribute. This field exists in the database table – it is the foreign key that connects Post and User. -
两个关系字段:数据库表中不存在
author和posts。关系字段定义 Prisma ORM 级别的模型之间的连接,仅存在于 Prisma 架构和生成的 Prisma 客户端中,用于访问关系。¥The two relation fields:
authorandpostsdo not exist in the database table. Relation fields define connections between models at the Prisma ORM level and exist only in the Prisma schema and generated Prisma Client, where they are used to access the relations.
Prisma 模式的声明性本质是简洁的,允许在 Prisma 客户端中定义数据库模式和相应的表示。
¥The declarative nature of Prisma schema is concise and allows defining the database schema and corresponding representation in Prisma Client.
在下一节中,你将了解 Prisma ORM 支持的工作流程。
¥In the next section, you will learn about Prisma ORM's supported workflows.
Prisma ORM 工作流程
¥Prisma ORM workflow
Prisma ORM 的工作流程与传统 ORM 略有不同。从头开始构建新应用或逐步采用它时,你可以使用 Prisma ORM:
¥The workflow with Prisma ORM is slightly different to traditional ORMs. You can use Prisma ORM when building new applications from scratch or adopt it incrementally:
-
新应用(绿地):还没有数据库架构的项目可以使用 Prisma Migrate 创建数据库架构。
¥New application (greenfield): Projects that have no database schema yet can use Prisma Migrate to create the database schema.
-
现有应用(棕地):已经拥有数据库模式的项目可以通过 Prisma ORM 进行 introspected 来生成 Prisma 模式和 Prisma 客户端。该用例可与任何现有迁移工具配合使用,对于增量采用非常有用。可以切换到 Prisma Migrate 作为迁移工具。然而,这是可选的。
¥Existing application (brownfield): Projects that already have a database schema can be introspected by Prisma ORM to generate the Prisma schema and Prisma Client. This use-case works with any existing migration tool and is useful for incremental adoption. It's possible to switch to Prisma Migrate as the migration tool. However, this is optional.
对于这两个工作流程,Prisma 架构是主要配置文件。
¥With both workflows, the Prisma schema is the main configuration file.
在具有现有数据库的项目中增量采用的工作流程
¥Workflow for incremental adoption in projects with an existing database
棕地项目通常已经有一些数据库抽象和模式。Prisma ORM 可以通过内省现有数据库来与此类项目集成,以获得反映现有数据库 schema 的 Prisma schema 并生成 Prisma Client。此工作流程与你可能已经在使用的任何迁移工具和 ORM 兼容。如果你喜欢逐步评估和采用,可以将此方法用作 并行采用策略 的一部分。
¥Brownfield projects typically already have some database abstraction and schema. Prisma ORM can integrate with such projects by introspecting the existing database to obtain a Prisma schema that reflects the existing database schema and to generate Prisma Client. This workflow is compatible with any migration tool and ORM which you may already be using. If you prefer to incrementally evaluate and adopt, this approach can be used as part of a parallel adoption strategy.
与此工作流程兼容的设置的非详尽列表:
¥A non-exhaustive list of setups compatible with this workflow:
-
使用带有
CREATE TABLE和ALTER TABLE的纯 SQL 文件来创建和更改数据库架构的项目。¥Projects using plain SQL files with
CREATE TABLEandALTER TABLEto create and alter the database schema. -
使用第三方迁移库(如 db-migrate 或 乌姆祖格)的项目。
¥Projects using a third party migration library like db-migrate or Umzug.
-
已经使用 ORM 的项目。在这种情况下,通过 ORM 的数据库访问保持不变,而生成的 Prisma Client 可以增量采用。
¥Projects already using an ORM. In this case, database access through the ORM remains unchanged while the generated Prisma Client can be incrementally adopted.
在实践中,以下是内省现有数据库并生成 Prisma 客户端所需的步骤:
¥In practice, these are the steps necessary to introspect an existing DB and generate Prisma Client:
-
创建一个定义
datasource(在本例中为你现有的数据库)和generator的schema.prisma:¥Create a
schema.prismadefining thedatasource(in this case, your existing DB) andgenerator:
datasource db {
provider = "postgresql"
url = "postgresql://janedoe:janedoe@localhost:5432/hello-prisma"
}
generator client {
provider = "prisma-client"
output = "./generated"
}
-
运行
prisma db pull以使用从数据库架构派生的模型填充 Prisma 架构。¥Run
prisma db pullto populate the Prisma schema with models derived from your database schema. -
(可选的)自定义 Prisma 客户端和数据库之间的 字段和模型映射。
¥(Optional) Customize field and model mappings between Prisma Client and the database.
-
运行
prisma generate。¥Run
prisma generate.
Prisma ORM 将在 node_modules 文件夹中生成 Prisma 客户端,可以从该文件夹将其导入到你的应用中。有关更广泛的使用文档,请参阅 Prisma 客户端 API 文档。
¥Prisma ORM will generate Prisma Client inside the node_modules folder, from which it can be imported in your application. For more extensive usage documentation, see the Prisma Client API docs.
总而言之,Prisma 客户端可以集成到具有现有数据库和工具的项目中,作为并行采用策略的一部分。新项目将使用下面详细介绍的不同工作流程。
¥To summarize, Prisma Client can be integrated into projects with an existing database and tooling as part of a parallel adoption strategy. New projects will use a different workflow detailed next.
新项目的工作流程
¥Workflow for new projects
Prisma ORM 与 ORM 的不同之处在于它支持的工作流程。仔细查看创建和更改新数据库架构所需的步骤对于理解 Prisma Migrate 非常有用。
¥Prisma ORM is different from ORMs in terms of the workflows it supports. A closer look at the steps necessary to create and change a new database schema is useful for understanding Prisma Migrate.
Prisma Migrate 是用于声明性数据建模和迁移的 CLI。与作为 ORM 一部分的大多数迁移工具不同,你只需要描述当前模式,而不需要从一种状态移动到另一种状态的操作。Prisma Migrate 会推断操作、生成 SQL 并为你执行迁移。
¥Prisma Migrate is a CLI for declarative data modeling & migrations. Unlike most migration tools that come as part of an ORM, you only need to describe the current schema, instead of the operations to move from one state to another. Prisma Migrate infers the operations, generates the SQL and carries out the migration for you.
此示例演示了在新项目中使用 Prisma ORM 和新的数据库架构,类似于上面的博客示例:
¥This example demonstrates using Prisma ORM in a new project with a new database schema similar to the blog example above:
-
创建 Prisma 架构:
¥Create the Prisma schema:
// schema.prisma
datasource db {
provider = "postgresql"
url = "postgresql://janedoe:janedoe@localhost:5432/hello-prisma"
}
generator client {
provider = "prisma-client"
output = "./generated"
}
model Post {
id Int @id @default(autoincrement())
title String
content String? @map("post_content")
published Boolean @default(false)
author User? @relation(fields: [authorId], references: [id])
authorId Int?
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
}
-
运行
prisma migrate生成迁移的 SQL,将其应用到数据库,并生成 Prisma 客户端。¥Run
prisma migrateto generate the SQL for the migration, apply it to the database, and generate Prisma Client.
对于数据库架构的任何进一步更改:
¥For any further changes to the database schema:
-
将更改应用于 Prisma 架构,例如,将
registrationDate字段添加到User模型¥Apply changes to the Prisma schema, e.g., add a
registrationDatefield to theUsermodel -
再次运行
prisma migrate。¥Run
prisma migrateagain.
最后一步演示了声明式迁移如何工作,方法是向 Prisma 架构添加字段并使用 Prisma Migrate 将数据库架构转换为所需状态。运行迁移后,Prisma 客户端会自动重新生成,以反映更新后的架构。
¥The last step demonstrates how declarative migrations work by adding a field to the Prisma schema and using Prisma Migrate to transform the database schema to the desired state. After the migration is run, Prisma Client is automatically regenerated so that it reflects the updated schema.
如果你不想使用 Prisma Migrate,但仍想在新项目中使用类型安全生成的 Prisma Client,请参阅下一节。
¥If you don't want to use Prisma Migrate but still want to use the type-safe generated Prisma Client in a new project, see the next section.
无需 Prisma Migrate 的新项目的替代方案
¥Alternative for new projects without Prisma Migrate
可以在新项目中使用 Prisma Client 和第三方迁移工具而不是 Prisma Migrate。例如,一个新项目可以选择使用 Node.js 迁移框架 db-migrate 来创建数据库架构和迁移,并使用 Prisma 客户端进行查询。本质上,现有数据库的工作流程 涵盖了这一点。
¥It is possible to use Prisma Client in a new project with a third-party migration tool instead of Prisma Migrate. For example, a new project could choose to use the Node.js migration framework db-migrate to create the database schema and migrations and Prisma Client for querying. In essence, this is covered by the workflow for existing databases.
使用 Prisma 客户端访问数据
¥Accessing data with Prisma Client
到目前为止,本文介绍了 Prisma ORM 背后的概念、其数据映射器模式的实现及其支持的工作流程。在最后一部分中,你将了解如何使用 Prisma 客户端访问应用中的数据。
¥So far, the article covered the concepts behind Prisma ORM, its implementation of the Data Mapper pattern, and the workflows it supports. In this last section, you will see how to access data in your application using Prisma Client.
使用 Prisma Client 访问数据库是通过其公开的查询方法进行的。所有查询都返回普通的旧 JavaScript 对象。给定上面的博客架构,获取用户如下所示:
¥Accessing the database with Prisma Client happens through the query methods it exposes. All queries return plain old JavaScript objects. Given the blog schema from above, fetching a user looks as follows:
import { PrismaClient } from '../prisma/generated/client'
const prisma = new PrismaClient()
const user = await prisma.user.findUnique({
where: {
email: 'alice@prisma.io',
},
})
在此查询中,findUnique() 方法用于从 User 表中获取单行。默认情况下,Prisma ORM 将返回 User 表中的所有标量字段。
¥In this query, the findUnique() method is used to fetch a single row from the User table. By default, Prisma ORM will return all the scalar fields in the User table.
注意:该示例使用 TypeScript 来充分利用 Prisma Client 提供的类型安全功能。然而,Prisma ORM 也适用于 Node.js 中的 JavaScript。
¥Note: The example uses TypeScript to make full use of the type safety features offered by Prisma Client. However, Prisma ORM also works with JavaScript in Node.js.
Prisma 客户端通过从 Prisma 架构生成代码将查询和结果映射到 结构类型。这意味着 user 在生成的 Prisma 客户端中有关联类型:
¥Prisma Client maps queries and results to structural types by generating code from the Prisma schema. This means that user has an associated type in the generated Prisma Client:
export type User = {
id: number
email: string
name: string | null
}
这确保访问不存在的字段将引发类型错误。更广泛地说,这意味着在运行查询之前就知道每个查询的结果类型,这有助于捕获错误。例如,以下代码片段将引发类型错误:
¥This ensures that accessing a non-existent field will raise a type error. More broadly, it means that the result's type for every query is known ahead of running the query, which helps catch errors. For example, the following code snippet will raise a type error:
console.log(user.lastName) // Property 'lastName' does not exist on type 'User'.
获取关系
¥Fetching relations
使用 include 选项获取与 Prisma 客户端的关系。例如,要获取用户及其帖子,请按如下方式完成:
¥Fetch relations with Prisma Client is done with the include option. For example, to fetch a user and their posts would be done as follows:
const user = await prisma.user.findUnique({
where: {
email: 'alice@prisma.io',
},
include: {
posts: true,
},
})
通过此查询,user 的类型还将包括 Post,可以通过 posts 数组字段访问:
¥With this query, user's type will also include Posts which can be accessed with the posts array field:
console.log(user.posts[0].title)
该示例仅涉及 增删改查操作 的 Prisma Client API 的皮毛,你可以在文档中了解更多信息。主要思想是所有查询和结果都由类型支持,并且你可以完全控制如何获取关系。
¥The example only scratches the surface of Prisma Client's API for CRUD operations which you can learn more about in the docs. The main idea is that all queries and results are backed by types and you have full control over how relations are fetched.
结论
¥Conclusion
总之,Prisma ORM 是一种新型的数据映射器 ORM,它不同于传统的 ORM,并且不会遇到与之相关的常见问题。
¥In summary, Prisma ORM is a new kind of Data Mapper ORM that differs from traditional ORMs and doesn't suffer from the problems commonly associated with them.
与传统的 ORM 不同,使用 Prisma ORM,你可以定义 Prisma 架构 - 数据库架构和应用模型的声明性单一事实来源。Prisma Client 中的所有查询都会返回纯 JavaScript 对象,这使得与数据库交互的过程更加自然且更可预测。
¥Unlike traditional ORMs, with Prisma ORM, you define the Prisma schema – a declarative single source of truth for the database schema and application models. All queries in Prisma Client return plain JavaScript objects which makes the process of interacting with the database a lot more natural as well as more predictable.
Prisma ORM 支持启动新项目和在现有项目中采用两种主要工作流程。对于这两种工作流程,配置的主要途径是通过 Prisma 模式。
¥Prisma ORM supports two main workflows for starting new projects and adopting in an existing project. For both workflows, your main avenue for configuration is via the Prisma schema.
与所有抽象一样,Prisma ORM 和其他 ORM 都通过不同的假设隐藏了数据库的一些底层细节。
¥Like all abstractions, both Prisma ORM and other ORMs hide away some of the underlying details of the database with different assumptions.
这些差异和你的用例都会影响工作流程和采用成本。希望了解它们的不同之处可以帮助你做出明智的决定。
¥These differences and your use case all affect the workflow and cost of adoption. Hopefully understanding how they differ can help you make an informed decision.