什么是内省?
你可以使用 Prisma CLI 内省数据库,以便在 Prisma 架构 中生成 数据模型。生成 Prisma 客户端 需要数据模型。
¥You can introspect your database using the Prisma CLI in order to generate the data model in your Prisma schema. The data model is needed to generate Prisma Client.
内省通常用于在 将 Prisma ORM 添加到现有项目.1 时生成数据模型的初始版本。
¥Introspection is often used to generate an initial version of the data model when adding Prisma ORM to an existing project.
然而,它也可以是 在应用中重复使用。当你不使用 Prisma 迁移 但使用纯 SQL 或其他迁移工具执行架构迁移时,最常见的情况是。在这种情况下,你还需要重新检查数据库并随后重新生成 Prisma 客户端以反映 Prisma 客户端 API 中的架构更改。
¥However, it can also be used repeatedly in an application. This is most commonly the case when you're not using Prisma Migrate but perform schema migrations using plain SQL or another migration tool. In that case, you also need to re-introspect your database and subsequently re-generate Prisma Client to reflect the schema changes in your Prisma Client API.
内省有什么作用?
¥What does introspection do?
内省有一个主要功能:使用反映当前数据库架构的数据模型填充 Prisma 架构。
¥Introspection has one main function: Populate your Prisma schema with a data model that reflects the current database schema.
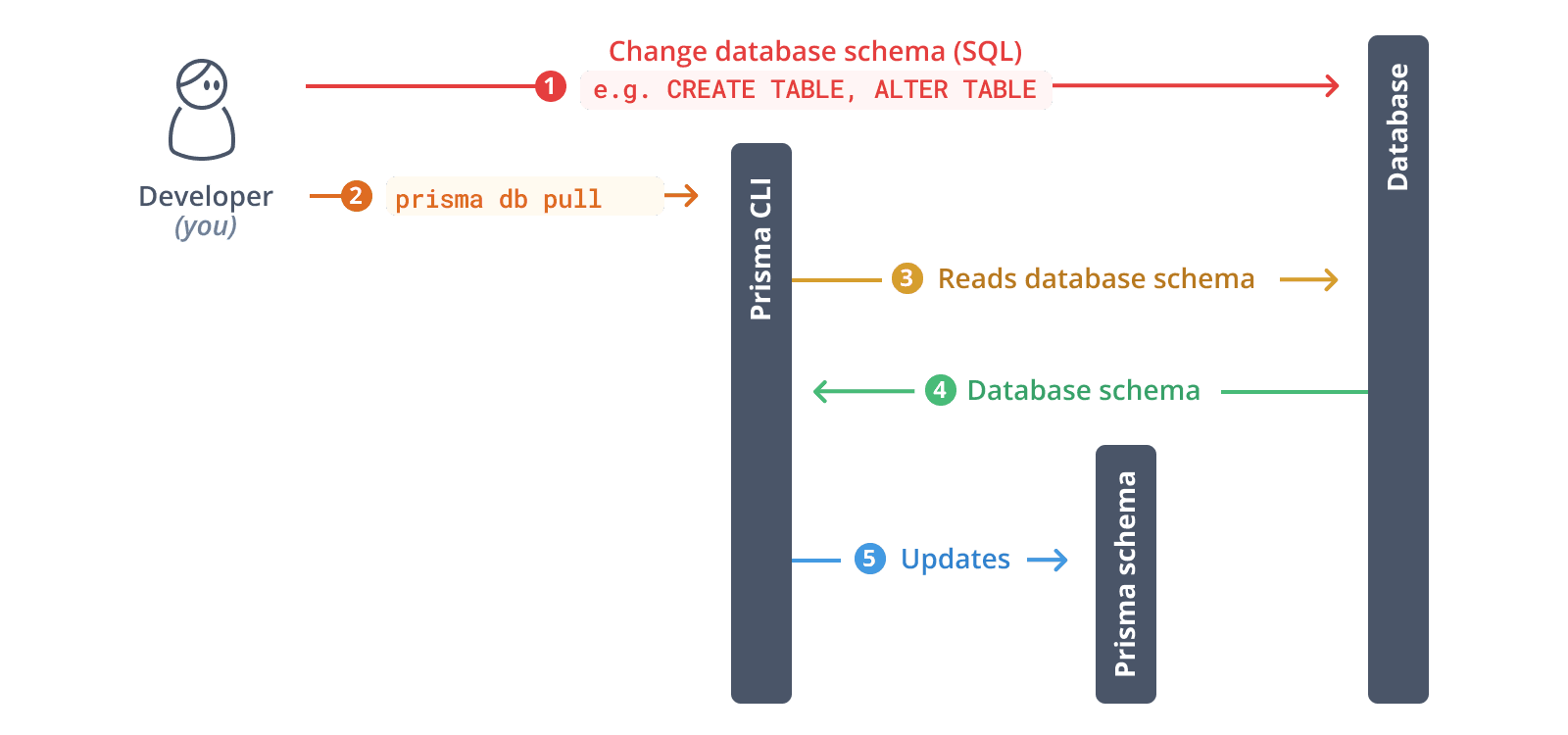
以下是其在 SQL 数据库上的主要功能概述:
¥Here's an overview of its main functions on SQL databases:
-
将数据库中的表映射到 Prisma 型号
¥Map tables in the database to Prisma models
-
将数据库中的列映射到 Prisma 模型的 fields
¥Map columns in the database to the fields of Prisma models
-
将数据库中的索引映射到 Prisma 模式中的 indexes
¥Map indexes in the database to indexes in the Prisma schema
-
将数据库约束映射到 Prisma 模式中的 attributes 或 类型修饰符
¥Map database constraints to attributes or type modifiers in the Prisma schema
在 MongoDB 上,主要功能如下:
¥On MongoDB, the main functions are the following:
-
将数据库中的集合映射到 Prisma 型号。由于 MongoDB 中的集合没有预定义的结构,因此 Prisma ORM 会对集合中的文档进行采样并相应地得出模型结构(即它将文档的字段映射到 Prisma 模型的 fields)。如果在集合中检测到嵌入类型,这些类型将映射到 Prisma 模式中的 复合类型。
¥Map collections in the database to Prisma models. Because a collection in MongoDB doesn't have a predefined structure, Prisma ORM samples the documents in the collection and derives the model structure accordingly (i.e. it maps the fields of the document to the fields of the Prisma model). If embedded types are detected in a collection, these will be mapped to composite types in the Prisma schema.
-
将数据库中的索引映射到 Prisma schema 中的 indexes,如果集合中至少有一个文档包含索引中包含的字段
¥Map indexes in the database to indexes in the Prisma schema, if the collection contains at least one document contains a field included in the index
你可以在数据源连接器的相应文档页面上详细了解 Prisma ORM 如何将数据库中的类型映射到 Prisma 架构中可用的类型:
¥You can learn more about how Prisma ORM maps types from the database to the types available in the Prisma schema on the respective docs page for the data source connector:
prisma db pull 命令
¥The prisma db pull command
你可以使用 Prisma CLI 的 prisma db pull 命令内省数据库。请注意,使用此命令需要你在 Prisma 配置 datasource 中设置 连接网址。
¥You can introspect your database using the prisma db pull command of the Prisma CLI. Note that using this command requires your connection URL to be set in your Prisma config datasource.
以下是 prisma db pull 内部执行步骤的高级概述:
¥Here's a high-level overview of the steps that prisma db pull performs internally:
-
从 Prisma 配置中的
datasource配置读取 连接网址¥Read the connection URL from the
datasourceconfiguration in the Prisma config -
打开与数据库的连接
¥Open a connection to the database
-
内省数据库模式(即读取表、列和其他结构......)
¥Introspect database schema (i.e. read tables, columns and other structures ...)
-
将数据库模式转换为 Prisma 模式数据模型
¥Transform database schema into Prisma schema data model
-
将数据模型写入 Prisma schema 或 更新现有架构
¥Write data model into Prisma schema or update existing schema
自省工作流程
¥Introspection workflow
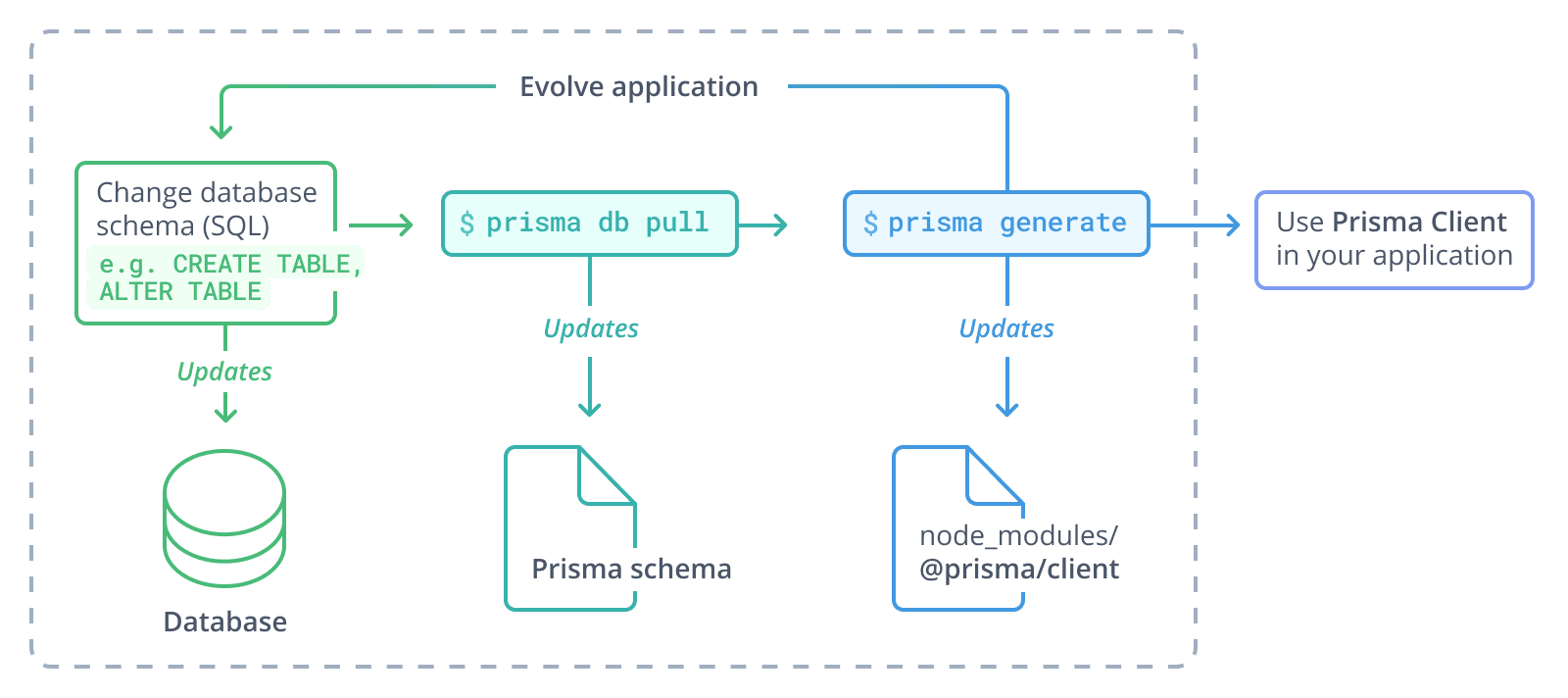
不使用 Prisma Migrate、而是使用纯 SQL 或其他迁移工具的项目的典型工作流程如下所示:
¥The typical workflow for projects that are not using Prisma Migrate, but instead use plain SQL or another migration tool looks as follows:
-
更改数据库架构(例如使用纯 SQL)
¥Change the database schema (e.g. using plain SQL)
-
运行
prisma db pull以更新 Prisma 架构¥Run
prisma db pullto update the Prisma schema -
运行
prisma generate更新 Prisma 客户端¥Run
prisma generateto update Prisma Client -
在你的应用中使用更新的 Prisma 客户端
¥Use the updated Prisma Client in your application
请注意,随着应用的发展,这个过程可以重复无限次.
¥Note that as you evolve the application, this process can be repeated for an indefinite number of times.
规则和约定
¥Rules and conventions
Prisma ORM 采用多种约定将数据库模式转换为 Prisma 模式中的数据模型:
¥Prisma ORM employs a number of conventions for translating a database schema into a data model in the Prisma schema:
模型、字段和枚举名称
¥Model, field and enum names
字段、模型和枚举名称(标识符)必须以字母开头,并且通常只能包含下划线、字母和数字。你可以在相应的文档页面上找到每个标识符的命名规则和约定:
¥Field, model and enum names (identifiers) must start with a letter and generally must only contain underscores, letters and digits. You can find the naming rules and conventions for each of these identifiers on the respective docs page:
标识符的一般规则是它们需要遵守以下正则表达式:
¥The general rule for identifiers is that they need to adhere to this regular expression:
[A-Za-z][A-Za-z0-9_]*
无效字符的清理
¥Sanitization of invalid characters
在内省期间正在清理无效字符:
¥Invalid characters are being sanitized during introspection:
-
如果它们出现在标识符中的字母之前,它们就会被删除。
¥If they appear before a letter in an identifier, they get dropped.
-
如果它们出现在第一个字母之后,则会被下划线替换。
¥If they appear after the first letter, they get replaced by an underscore.
此外,转换后的名称会使用 @map 或 @@map 映射到数据库以保留原始名称。
¥Additionally, the transformed name is mapped to the database using @map or @@map to retain the original name.
以下表为例:
¥Consider the following table as an example:
CREATE TABLE "42User" (
_id SERIAL PRIMARY KEY,
_name VARCHAR(255),
two$two INTEGER
);
由于 Prisma ORM 中禁止表名称中的前导 42 以及前导下划线和列上的 $,因此内省添加了 @map 和 @@map 属性,以便这些名称遵循 Prisma ORM 的命名约定:
¥Because the leading 42 in the table name as well as the leading underscores and the $ on the columns are forbidden in Prisma ORM, introspection adds the @map and @@map attributes so that these names adhere to Prisma ORM's naming conventions:
model User {
id Int @id @default(autoincrement()) @map("_id")
name String? @map("_name")
two_two Int? @map("two$two")
@@map("42User")
}
清理后的重复标识符
¥Duplicate Identifiers after Sanitization
如果清理导致重复的标识符,则不会立即进行错误处理。你稍后会收到错误并可以手动修复它。
¥If sanitization results in duplicate identifiers, no immediate error handling is in place. You get the error later and can manually fix it.
考虑以下两个表的情况:
¥Consider the case of the following two tables:
CREATE TABLE "42User" (
_id SERIAL PRIMARY KEY
);
CREATE TABLE "24User" (
_id SERIAL PRIMARY KEY
);
这将导致以下内省结果:
¥This would result in the following introspection result:
model User {
id Int @id @default(autoincrement()) @map("_id")
@@map("42User")
}
model User {
id Int @id @default(autoincrement()) @map("_id")
@@map("24User")
}
尝试使用 prisma generate 生成 Prisma 客户端,你会收到以下错误:
¥Trying to generate your Prisma Client with prisma generate you would get the following error:
npx prisma generate
$ npx prisma generate
Error: Schema parsing
error: The model "User" cannot be defined because a model with that name already exists.
--> schema.prisma:17
|
16 | }
17 | model User {
|
Validation Error Count: 1
在这种情况下,你必须手动更改两个生成的 User 模型之一的名称,因为 Prisma 架构中不允许重复的模型名称。
¥In this case, you must manually change the name of one of the two generated User models because duplicate model names are not allowed in the Prisma schema.
字段顺序
¥Order of fields
自省以与数据库中相应表列相同的顺序列出模型字段。
¥Introspection lists model fields in the same order as the corresponding table columns in the database.
属性顺序
¥Order of attributes
内省按以下顺序添加属性(该顺序由 prisma format 镜像):
¥Introspection adds attributes in the following order (this order is mirrored by prisma format):
-
块级别:
@@id、@@unique、@@index、@@map¥Block level:
@@id,@@unique,@@index,@@map -
字段级别:
@id、@unique、@default、@updatedAt、@map、@relation¥Field level :
@id,@unique,@default,@updatedAt,@map,@relation
关系
¥Relations
Prisma ORM 将数据库表上定义的外键转换为 relations。
¥Prisma ORM translates foreign keys that are defined on your database tables into relations.
一对一的关系
¥One-to-one relations
当表上的外键具有 UNIQUE 约束时,Prisma ORM 会向你的数据模型添加 one-to-one 关系,例如:
¥Prisma ORM adds a one-to-one relation to your data model when the foreign key on a table has a UNIQUE constraint, e.g.:
CREATE TABLE "User" (
id SERIAL PRIMARY KEY
);
CREATE TABLE "Profile" (
id SERIAL PRIMARY KEY,
"user" integer NOT NULL UNIQUE,
FOREIGN KEY ("user") REFERENCES "User"(id)
);
Prisma ORM 将其转换为以下数据模型:
¥Prisma ORM translates this into the following data model:
model User {
id Int @id @default(autoincrement())
Profile Profile?
}
model Profile {
id Int @id @default(autoincrement())
user Int @unique
User User @relation(fields: [user], references: [id])
}
一对多关系
¥One-to-many relations
默认情况下,Prisma ORM 会为其在数据库模式中找到的外键添加 one-to-many 关系到你的数据模型:
¥By default, Prisma ORM adds a one-to-many relation to your data model for a foreign key it finds in your database schema:
CREATE TABLE "User" (
id SERIAL PRIMARY KEY
);
CREATE TABLE "Post" (
id SERIAL PRIMARY KEY,
"author" integer NOT NULL,
FOREIGN KEY ("author") REFERENCES "User"(id)
);
这些表被转换为以下模型:
¥These tables are transformed into the following models:
model User {
id Int @id @default(autoincrement())
Post Post[]
}
model Post {
id Int @id @default(autoincrement())
author Int
User User @relation(fields: [author], references: [id])
}
多对多关系
¥Many-to-many relations
¥Many-to-many relations are commonly represented as relation tables in relational databases.
Prisma ORM 支持两种在 Prisma 模式中定义多对多关系的方法:
¥Prisma ORM supports two ways for defining many-to-many relations in the Prisma schema:
-
隐式多对多关系(Prisma ORM 在底层管理关系表)
¥Implicit many-to-many relations (Prisma ORM manages the relation table under the hood)
-
¥Explicit many-to-many relations (the relation table is present as a model)
如果隐式多对多关系遵循 Prisma ORM 的 关系表的约定,则它们会被识别。否则,关系表将在 Prisma 模式中渲染为模型(因此使其成为显式多对多关系)。
¥Implicit many-to-many relations are recognized if they adhere to Prisma ORM's conventions for relation tables. Otherwise the relation table is rendered in the Prisma schema as a model (therefore making it an explicit many-to-many relation).
有关 关系 的文档页面广泛介绍了该主题。
¥This topic is covered extensively on the docs page about Relations.
消除关系歧义
¥Disambiguating relations
如果不需要,Prisma ORM 通常会省略 @relation 属性上的 name 参数。考虑上一节中的 User ↔ Post 示例。@relation 属性仅具有 references 参数,省略 name,因为在本例中不需要它:
¥Prisma ORM generally omits the name argument on the @relation attribute if it's not needed. Consider the User ↔ Post example from the previous section. The @relation attribute only has the references argument, name is omitted because it's not needed in this case:
model Post {
id Int @id @default(autoincrement())
author Int
User User @relation(fields: [author], references: [id])
}
如果 Post 表上定义了两个外键,则需要它:
¥It would be needed if there were two foreign keys defined on the Post table:
CREATE TABLE "User" (
id SERIAL PRIMARY KEY
);
CREATE TABLE "Post" (
id SERIAL PRIMARY KEY,
"author" integer NOT NULL,
"favoritedBy" INTEGER,
FOREIGN KEY ("author") REFERENCES "User"(id),
FOREIGN KEY ("favoritedBy") REFERENCES "User"(id)
);
在这种情况下,Prisma ORM 需要使用专用关系名称进行 消除关系的歧义:
¥In this case, Prisma ORM needs to disambiguate the relation using a dedicated relation name:
model Post {
id Int @id @default(autoincrement())
author Int
favoritedBy Int?
User_Post_authorToUser User @relation("Post_authorToUser", fields: [author], references: [id])
User_Post_favoritedByToUser User? @relation("Post_favoritedByToUser", fields: [favoritedBy], references: [id])
}
model User {
id Int @id @default(autoincrement())
Post_Post_authorToUser Post[] @relation("Post_authorToUser")
Post_Post_favoritedByToUser Post[] @relation("Post_favoritedByToUser")
}
请注意,你可以将 Prisma-ORM 级别 关系字段重命名为你喜欢的任何名称,以便它在生成的 Prisma 客户端 API 中看起来更友好。
¥Note that you can rename the Prisma-ORM level relation field to anything you like so that it looks friendlier in the generated Prisma Client API.
使用现有模式进行内省
¥Introspection with an existing schema
使用现有 Prisma Schema 为关系数据库运行 prisma db pull 会将对模式所做的手动更改与对数据库所做的更改合并。(该功能在 2.6.0 版本中首次添加。)对于 MongoDB,目前内省仅针对初始数据模型进行一次。重复运行它会导致自定义更改丢失,如下所列。
¥Running prisma db pull for relational databases with an existing Prisma Schema merges manual changes made to the schema, with changes made in the database. (This functionality has been added for the first time with version 2.6.0.) For MongoDB, Introspection for now is meant to be done only once for the initial data model. Running it repeatedly will lead to loss of custom changes, as the ones listed below.
关系数据库的自省维护以下手动更改:
¥Introspection for relational databases maintains the following manual changes:
-
model块的顺序¥Order of
modelblocks -
enum块的顺序¥Order of
enumblocks -
评论
¥Comments
-
@map和@@map属性¥
@mapand@@mapattributes -
@updatedAt -
@default(cuid())(cuid()是 Prisma-ORM 级别的函数)¥
@default(cuid())(cuid()is a Prisma-ORM level function) -
@default(uuid())(uuid()是 Prisma-ORM 级别的函数)¥
@default(uuid())(uuid()is a Prisma-ORM level function) -
自定义
@relation名称¥Custom
@relationnames
注意:仅会选取数据库级别的模型之间的关系。这意味着必须有一个外键集。
¥Note: Only relations between models on the database level will be picked up. This means that there must be a foreign key set.
架构的以下属性由数据库确定:
¥The following properties of the schema are determined by the database:
-
model块内的字段顺序¥Order of fields within
modelblocks -
enum块内值的顺序¥Order of values within
enumblocks
注意:所有
enum块都列在model块下方。¥Note: All
enumblocks are listed belowmodelblocks.
强制覆盖
¥Force overwrite
要覆盖手动更改,并仅基于自省数据库生成模式并忽略任何现有的 Prisma Schema,请将 --force 标志添加到 db pull 命令:
¥To overwrite manual changes, and generate a schema based solely on the introspected database and ignore any existing Prisma Schema, add the --force flag to the db pull command:
npx prisma db pull --force
用例包括:
¥Use cases include:
-
你想要从头开始使用从底层数据库生成的模式
¥You want to start from scratch with a schema generated from the underlying database
-
你的架构无效,必须使用
--force才能使内省成功¥You have an invalid schema and must use
--forceto make introspection succeed
仅内省数据库架构的子集
¥Introspecting only a subset of your database schema
仅内省数据库模式的子集是 Prisma ORM 的 尚未正式支持。
¥Introspecting only a subset of your database schema is not yet officially supported by Prisma ORM.
但是,你可以通过创建一个新的数据库用户来实现此目的,该用户只能访问你希望在 Prisma 架构中看到的表,然后使用该用户执行内省。然后,内省将仅包括新用户有权访问的表。
¥However, you can achieve this by creating a new database user that only has access to the tables which you'd like to see represented in your Prisma schema, and then perform the introspection using that user. The introspection will then only include the tables the new user has access to.
如果你的目标是从 Prisma 客户端生成 中排除某些模型,你可以将 @@ignore 属性 添加到 Prisma 架构中的模型定义中。忽略的模型将从生成的 Prisma 客户端中排除。
¥If your goal is to exclude certain models from the Prisma Client generation, you can add the @@ignore attribute to the model definition in your Prisma schema. Ignored models are excluded from the generated Prisma Client.
针对不支持的功能的自省警告
¥Introspection warnings for unsupported features
Prisma 架构语言 (PSL) 可以表达 目标数据库 Prisma ORM 支持的大部分数据库功能。然而,Prisma 模式语言仍然需要表达一些特性和功能。
¥The Prisma Schema Language (PSL) can express a majority of the database features of the target databases Prisma ORM supports. However, there are features and functionality the Prisma Schema Language still needs to express.
对于这些功能,Prisma CLI 将检测数据库中该功能的使用情况并返回警告。Prisma CLI 还将在 Prisma 架构中使用的功能的模型和字段中添加注释。警告还将包含解决方法建议。
¥For these features, the Prisma CLI will surface detect usage of the feature in your database and return a warning. The Prisma CLI will also add a comment in the models and fields the features are in use in the Prisma schema. The warnings will also contain a workaround suggestion.
prisma db pull 命令将显示以下不受支持的功能:
¥The prisma db pull command will surface the following unsupported features:
-
从版本 4.13.0 开始:
¥From version 4.13.0:
-
从版本 4.14.0 开始:
¥From version 4.14.0:
-
检查约束(MySQL + PostgreSQL)
¥Check Constraints (MySQL + PostgreSQL)
-
-
从版本 4.16.0 开始:
¥From version 4.16.0:
你可以找到我们打算在 GitHub(标有 topic:database-functionality) 上支持的功能列表。
¥You can find the list of features we intend to support on GitHub (labeled with topic:database-functionality).
针对不支持的功能的内省警告的解决方法
¥Workaround for introspection warnings for unsupported features
如果你使用的是关系数据库并且具有上一节中列出的上述功能之一:
¥If you are using a relational database and either one of the above features listed in the previous section:
-
创建迁移草稿:
¥Create a draft migration:
npx prisma migrate dev --create-only -
添加用于添加警告中出现的功能的 SQL。
¥Add the SQL that adds the feature surfaced in the warnings.
-
将草稿迁移应用到你的数据库:
¥Apply the draft migration to your database:
npx prisma migrate dev